目录
- 1 主从读写分离
- 1.1 core
- 2 主从复制
- 2.1 主从复制的过程
- 2.2 主从复制的副作用
- 2.3 避免主从复制的延迟
- 2.3.1 数据冗余
- 2.3.2 使用Cache
- 2.3.3 查询主库
- 3 如何访问DB
- 3.1 应用程序内部
- 优点
- 缺点
- 3.2 独立部署的代理层方案
- 优点
- 缺点
- 4 总结
- FAQ
1 主从读写分离
大部分互联网业务都是读多写少,因此优先考虑DB如何支撑更高查询数,首先就需要区分读、写流量,这才方便针对读流量单独扩展,即主从读写分离。
若前端流量突增导致从库负载过高,DBA会优先做个从库扩容上去,这样对DB的读流量就会落到多个从库,每个从库的负载就降了下来,然后开发再尽力将流量挡在DB层之上。
Cache V.S MySQL读写分离
由于从开发和维护的难度考虑,引入缓存会引入复杂度,要考虑缓存数据一致性,穿透,防雪崩等问题,并且也多维护一类组件。所以推荐优先采用读写分离,扛不住了再使用Cache。
1.1 core
主从读写分离一般将一个DB的数据拷贝为一或多份,并且写入到其它的DB服务器中:
- 原始DB为主库,负责数据写入
- 拷贝目标DB为从库,负责数据查询
所以主从读写分离的关键:
- 数据的拷贝
即主从复制
- 屏蔽主从分离带来的访问DB方式的变化
让开发人员使用感觉依旧在使用单一DB
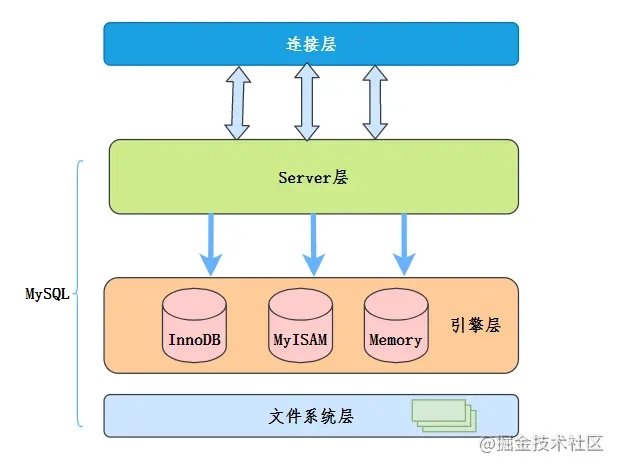
2 主从复制
MySQL的主从复制依赖于binlog,即记录MySQL上的所有变化并以二进制形式保存在磁盘上二进制日志文件。
主从复制就是将binlog中的数据从主库传输到从库,一般异步:主库操作不会等待binlog同步完成。
2.1 主从复制的过程
- 从库在连接到主节点时会创建一个I/O线程,以请求主库更新的binlog,并把接收到的binlog写入relay log文件,主库也会创建一个log dump线程发送binlog给从库
- 从库还会创建一个SQL线程,读relay log,并在从库中做回放,最终实现主从的一致性
使用独立的log dump线程是异步,避免影响主库的主体更新流程,而从库在接收到信息后并不是写入从库的存储,是写入一个relay log,这是为避免写入从库实际存储会比较耗时,最终造成从库和主库延迟变长。
- 主从异步复制的过程
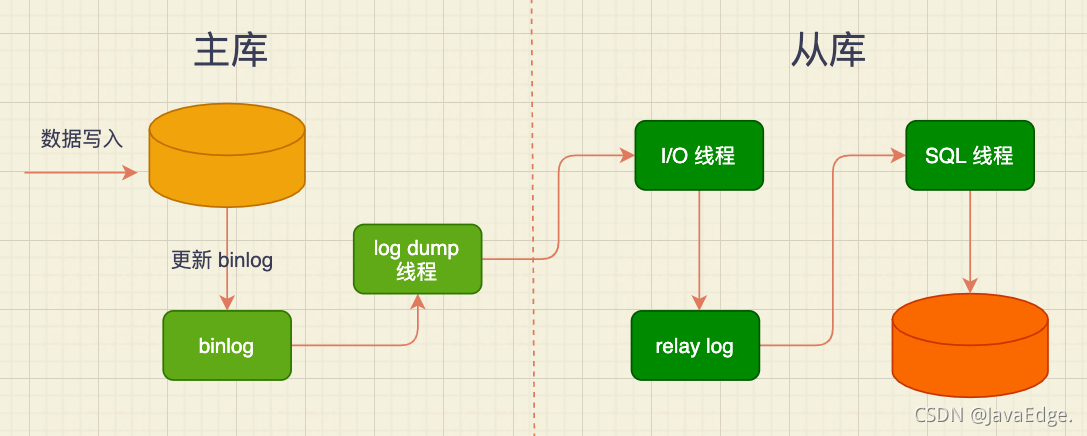
基于性能考虑,主库写入流程并没有等待主从同步完成就返回结果,极端情况下,比如主库上binlog还没来得及落盘,就发生磁盘损坏或机器掉电,导致binlog丢失,主从数据不一致。不过概率很低,可容忍。
主库宕机后,binlog丢失导致的主从数据不一致也只能手动恢复。
主从复制后,即可:
- 在写入时只写主库
- 在读数据时只读从库
这样即使写请求会锁表或锁记录,也不会影响读请求执行。高并发下,可部署多个从库共同承担读流量,即一主多从支撑高并发读。
从库也能当成个备库,以避免主库故障导致数据丢失。
那无限制地增加从库就能支撑更高并发吗?
NO!从库越多,从库连接上来的I/O线程越多,主库也要创建同样多log dump线程处理复制的请求,对于主库资源消耗较高,同时受限于主库的网络带宽,所以一般一个主库最多挂3~5个从库。
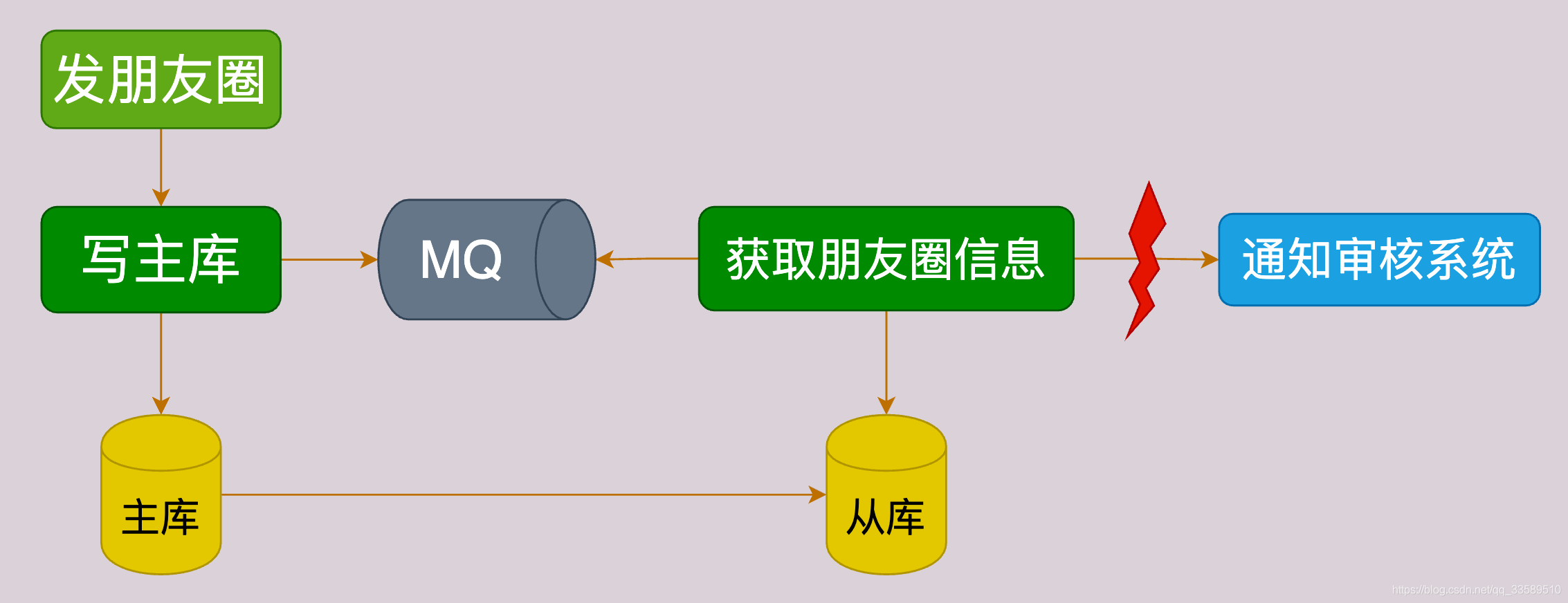
2.2 主从复制的副作用
比如发朋友圈这一操作,就存在数据的:
- 同步操作
如更新DB
- 异步操作
如将朋友圈内容同步给审核系统
所以更新完主库后,会将朋友圈ID写入MQ,由Consumer依据ID在从库获取朋友圈信息再发给审核系统。
此时若主从DB存在延迟,会导致在从库取不到朋友圈信息,出现异常!
主从延迟对业务的影响示意图
2.3 避免主从复制的延迟
这咋办呢?其实解决方案有很多,核心思想都是 尽量不去从库查询数据。因此针对上述案例,就有如下方案:
2.3.1 数据冗余
可在发MQ时,不止发送朋友圈ID,而是发给Consumer需要的所有朋友圈信息,避免从DB重新查询数据。
推荐该方案,因为足够简单,不过可能造成单条消息较大,从而增加消息发送的带宽和时间。
2.3.2 使用Cache
在同步写DB的同时,把朋友圈数据写Cache,这样Consumer在获取朋友圈信息时,优先查询Cache,这也能保证数据一致性。
该方案适合新增数据的场景。若是在更新数据场景下,先更新Cache可能导致数据不一致。比如两个线程同时更新数据:
- 线程A把Cache数据更新为1
- 另一个线程B把Cache数据更新为2
- 然后线程B又更新DB数据为2
- 线程A再更新DB数据为1
最终DB值(1)和Cache值(2)不一致!
2.3.3 查询主库
可以在Consumer中不查询从库,而改为查询主库。
使用要慎重,要明确查询的量级不会很大,是在主库的可承受范围之内,否则会对主库造成较大压力。
若非万不得已,不要使用该方案。因为要提供一个查询主库的接口,很难保证其他人不滥用该方法。
主从同步延迟也是排查问题时容易忽略。
有时会遇到从DB获取不到信息的诡异问题,会纠结代码中是否有一些逻辑把之前写入内容删除了,但发现过段时间再去查询时又能读到数据,这基本就是主从延迟问题。
所以,一般把从库落后的时间作为一个重点DB指标,做监控和报警,正常时间在ms级,达到s级就要告警。
主从的延迟时间预警,那如何通过哪个数据库中的哪个指标来判别? 在从从库中,通过监控show slave
status\G命令输出的Seconds_Behind_Master参数的值判断,是否有发生主从延时。
这个参数值是通过比较sql_thread执行的event的timestamp和io_thread复制好的
event的timestamp(简写为ts)进行比较,而得到的这么一个差值。
但如果复制同步主库bin_log日志的io_thread线程负载过高,则Seconds_Behind_Master一直为0,即无法预警,通过Seconds_Behind_Master这个值来判断延迟是不够准确。其实还可以通过比对master和slave的binlog位置。
3 如何访问DB
使用主从复制将数据复制到多个节点,也实现了DB的读写分离,这时,对DB的使用也发生了变化:
- 以前只需使用一个DB地址
- 现在需使用一个主库地址,多个从库地址,且需区分写入操作和查询操作,再结合“分库分表”,复杂度大大提升。
为降低实现的复杂度,业界涌现了很多DB中间件解决DB的访问问题,大致分为:
3.1 应用程序内部
如TDDL( Taobao Distributed Data Layer),以代码形式内嵌运行在应用程序内部。可看成是一种数据源代理,它的配置管理多个数据源,每个数据源对应一个DB,可能是主库或从库。
当有一个DB请求时,中间件将SQL语句发给某个指定数据源,然后返回处理结果。
优点
简单易用,部署成本低,因为植入应用程序内部,与程序一同运行,适合运维较弱的小团队。
缺点
缺乏多语言支持,都是Java语言开发的,无法支持其他的语言。版本升级也依赖使用方的更新。
3.2 独立部署的代理层方案
如Mycat、Atlas、DBProxy。
这类中间件部署在独立服务器,业务代码如同在使用单一DB,实际上它内部管理着很多的数据源,当有DB请求时,它会对SQL语句做必要的改写,然后发往指定数据源。
优点
- 一般使用标准MySQL通信协议,所以可支持多种语言
- 独立部署,所以方便维护升级,适合有运维能力的大中型团队
缺点
- 所有的SQL语句都需要跨两次网络:从应用到代理层和从代理层到数据源,所以在性能上会有一些损耗。
4 总结
可以把主从复制引申为存储节点之间互相复制存储数据的技术,可以实现数据冗余,以达到备份和提升横向扩展能力。
使用主从复制时,需考虑:
- 主从的一致性和写入性能的权衡
若保证所有从节点都写入成功,则写性能一定受影响;若只写主节点就返回成功,则从节点就可能出现数据同步失败,导致主从不一致。互联网项目,一般优先考虑性能而非数据的强一致性
- 主从的延迟
会导致很多诡异的读取不到数据的问题
很多实际案例:
- Redis通过主从复制实现读写分离
- Elasticsearch中存储的索引分片也可被复制到多个节点
- 写入到HDFS中,文件也会被复制到多个DataNode中
不同组件对于复制的一致性、延迟要求不同,采用的方案也不同,但设计思想是相通的。
FAQ
若大量订单,通过userId hash到不同库,对前台用户订单查询有利,但后台系统页面需查看全部订单且排序,SQL执行就很慢。这该怎么办呢?
由于后台系统不能直接查询分库分表的数据,可考虑将数据同步至一个单独的后台库或同步至ES。
到此这篇关于MySQL如何支撑起亿级流量的文章就介绍到这了,更多相关MySQL 亿级流量内容请搜索NICE源码以前的文章或继续浏览下面的相关文章希望大家以后多多支持NICE源码!